How to work with JSON in Pandas
JSON is widely used format for storing the data and exchanging. Many of the API’s response are JSON and being light weight it’s used almost everywhere
In this post we will learn how to import a JSON File, JSON String, JSON API Response and import it to Pandas dataframe and work with it.
Pandas has built-in function read_json to import the JSON Strings and Files into pandas dataframe and json_normalize function works with nested json but it’s little hard to understand how to use it. We will understand that hard part in a simpler way in this post
Pandas Read_JSON
You can read a JSON string and convert it into a pandas dataframe using read_json() function. Here is a json string stored in variable data
data = '''[{
"_id": "26",
"Description": "10 YEAR",
"TypeLevel1": "INTEREST",
"Currency": "USD",
"Operational": true,
"TypeLevel2": "LONG",
"Settlement": "90",
"SCSP": "Rajna",
"BBT": "CITITYM9",
"TCK": "ZN",
"SMCP": "01",
"SMCP2": "02"
},
{
"_id": "27",
"Description": "5 YEAR",
"TypeLevel1": "PRINCIPAL",
"Currency": "GNP",
"Operational": false,
"TypeLevel2": "LONG",
"Settlement": "40",
"SCSP": "Paus",
"BBT": "CITITYM10",
"TCK": "PY",
"SMCP": "05",
"SMCP2": "09"
}]'''
We’ve imported the json string in data variable and specified the orient parameter as columns. it basically tells what is the format of the expected json. We will see how to use the orient columns while reading the json data in next section
pd.read_json(data,orient='columns')

orient parameter in read_json
orient parameter is set to define the format of the input JSON. As per the official documentation the orient parameter can be any of the following values
'split': dict like{index -> [index], columns -> [columns], data -> [values]}
'records': list like[{column -> value}, ... , {column -> value}]
'index': dict like{index -> {column -> value}}
'columns': dict like{column -> {index -> value}}
'values': just the values array
Let’s understand what are these orient value means
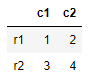
Let’s create a dataframe with index r1, r2 and column c1 and c2
df = pd.DataFrame([[1, 2], [3, 4]],
index=['r1', 'r2'],
columns=['c1', 'c2'])
orient index
We will change the dataframe to a JSON string and orient set to index
df.to_json(orient='index')
The output shows a json string with dataframe indexes as keys i.e. r1 & r2
Output: ‘{“r1”:{“c1”:1,”c2”:2},”r2”:{“c1”:3,”c2”:4}}’
orient split
This time we will set the orient value as split for the same dataframe
df.to_json(orient='split')
The output is a JSON String with keys as columns, index and data so basically it splitted the above dataframe into these three key and their corresponding values
**Output:** '{"columns":["c1","c2"],"index":["r1","r2"],"data":[[1,2],[3,4]]}'
orient records
if we set orient as records then it will give list of dictionary and each dictionary will contains the row values.
df.to_json(orient='records')
So here in the output column c1,c2 for row r1,r2 is displapyed inside the list
**Output:** '[{"c1":1,"c2":2},{"c1":3,"c2":4}]'
read json with orient
As shown above if we set the orient as any of the above strings then it will import the data accordingly
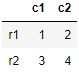
Going back to our read_json function above we have seen that setting the parameter orient index imports all the column values row wise
Similarly in this statement the json string values are imported as columns and the index is r1,r2 because the ouput above was ‘{“r1”:{“c1”:1,”c2”:2},”r2”:{“c1”:3,”c2”:4}}’
pd.read_json(_, orient='index')
Here the index changes to 0,1 because we have set the orient as records and all the values are imported as columns for each row because the output above for orient record is list of column values as dictionary ‘[{“c1”:1,”c2”:2},{“c1”:3,”c2”:4}]’
pd.read_json(_, orient='records')

JSON_Normalize function
Import nested JSON API Response using json_normalize
We are using openweather api to get the climate details for the next 30 days for the city of Mountain View in US
Use your api-key by registering to their site and convert the api response to python object
import requests
weather_json = requests.get("http://pro.openweathermap.org/data/2.5/climate/month?zip=94040,us&appid=<your_api_key>")
weather_api_data=json.loads(weather_json.text)
API Response
{'city': {'coord': {'lat': 37.3855, 'lon': -122.088},
'country': 'US',
'id': 0,
'name': 'Mountain View'},
'cod': '200',
'list': [{'dt': 1576108800,
'humidity': 76.85,
'pressure': 1019.38,
'temp': {'average': 282.94,
'average_max': 288.46,
'average_min': 280.05,
'record_max': 292.32,
'record_min': 272.48},
'wind_speed': 1.61}],
'message': 0.587190406}
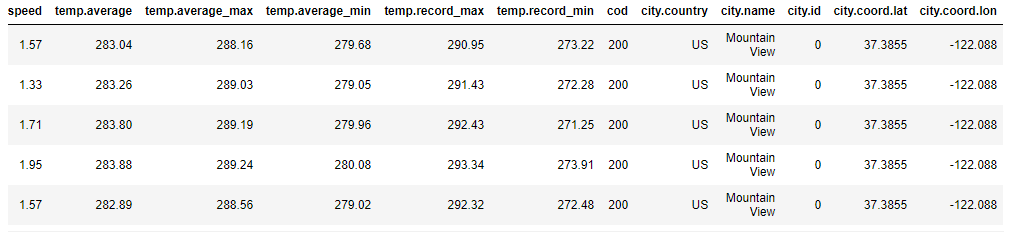
Use json_normalize() function to convert the api response into dataframe. In the next section we will understand how the record path and meta parameters are used to convert the nested json to dataframe
df=json_normalize(weather_api_data,['list'],meta=['cod',['city','country'],['city','name'],['city','id'],['city','coord','lat'],
['city','coord','lon']])
df.head()
Final Dataframe
how json_normalize works for nested JSON
record_path
We have to specify the Path in each object to list of records. In the above json “list” is the json object that contains list of json object which we want to import in the dataframe, basically list is the nested object in the entire json. so we specify this path under records_path
df=json_normalize(weather_api_data,record_path = ['list'])
meta
This contains the list of paths. So in our case we want all other objects which are outside “list” to be imported as dataframe column. So we have to specify all those column name as list i.e.
meta=['cod',['city','country'],['city','name'],['city','id'],['city','coord','lat'],
['city','coord','lon']]
You must be wondering why there are list inside that meta list like [‘city’,’country’] , [‘city’,’name’] etc.
If you check the above JSON, city is a json object which has coordinate, country, id and name fields inside it
So in order to import all those fields in the dataframe we have to specify that as a list inside the meta list like [‘city’,’coord’,’lat’] , [‘city’,’name’] etc.
In the dataframe those columns are shown as city.coord.lat and city.name
Another Example of nested json response using json_normalize
Let’s understand this using another example
Here is the nested JSON we want to import in a dataframe
data = {
"results": [
{
"_id": "25",
"Product": {
"Description": "3 YEAR",
"TypeLevel1": "INTEREST",
"TypeLevel2": "LONG"
},
"Settlement": {},
"Xref": {
"SCSP": "96",
"BBT":"81"
},
"ProductSMCP": [
{
"SMCP": "01"
}
]
},
{
"_id": "26",
"Product": {
"Description": "10 YEAR",
"TypeLevel1": "INTEREST",
"Currency": "USD",
"Operational": True,
"TypeLevel2": "LONG"
},
"Settlement": {},
"Xref": {
"SCSP": "Rajna",
"BBT": "CITITYM9",
"TCK": "ZN"
},
"ProductSMCP": [
{
"SMCP": "01"
},
{
"SMCP2": "02"
}
]
}
]
}
Our data is stored in results field, so we will use data[‘results’] as our dictionary item to be imported into dataframe
In this json we have field ProductSMCP which is a json array and we will pass that in record_path parameter
In the meta parameter we will pass other fields which we want to import in the dataframe i.e. meta = [‘Settlement’,[‘Xref’,’SCSP’],[‘Xref’,’BBT’],’_id’,[‘Product’,’Description’]]
Here is the complete line of code for importing this json into dataframe
json_normalize(data['results'],record_path=['ProductSMCP'],meta=['Settlement',['Xref','SCSP'],['Xref','BBT'],'_id',['Product','Description']])
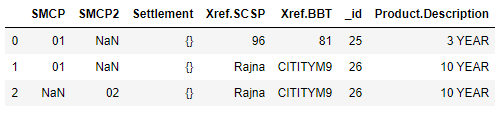
You cannot see other fields of Product like Typelevel1, Typelevel2 etc. because for this example I have never passed that inside the meta list
Conclusion:
So we have come to an end of this long post and we have seen different ways to import the regular and nested JSON into pandas dataframe using read_json() and json_normalize()
We have also seen how to import Json data from api response and json string directly into a pandas dataframe
if you have any comments or suggestions please feel free to drop a note in the comments section below