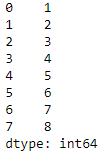How to remove duplicate data from python dataframe
Not all data are perfect and we really need to get duplicate data removed from our dataset most of the time. it looks easy to clean up the duplicate data but in reality it isn’t. Sometimes you want to just remove the duplicates from one or more columns and the other time you want to delete duplicates based on some random condition. So we will see in this post how to easily and efficiently you can remove the duplicate data using drop_duplicates() function in pandas
Create Dataframe with Duplicate data
import pandas as pd
df = pd.DataFrame({'Name' : ['John','Harry','Gary','Richard','Anna','Richard','Gary'], 'Age' : [25,32,37,43,44,56,37], 'Zone' : ['East','West','North','South','East','West','North']})

Drop the Duplicate rows
The row at index 2 and 6 in above dataframe are duplicates and all the three columns Name, Age and Zone matches for these two rows. Now we will remove all the duplicate rows from the dataframe using drop_duplicates() function
df.drop_duplicates()

Drop Duplicates from a specific Column and Keep last row
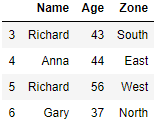
We will group the rows for each zone and just keep the last in each group i.e. For Zone East we have two rows in original dataframe i.e. index 0 and 4 and we want to keep only index 4 in this zone
df.drop_duplicates('Zone',keep='last')
Drop Duplicates from a specific Column and Keep first row
We will group the rows for each zone and just keep the first in each group i.e. For Zone East we have two rows in original dataframe i.e. index 0 and 4 and we want to keep only index 0 in this zone
df.drop_duplicates('Zone',keep='first')

Drop all Duplicates from a specific Column
We will drop the zone wise duplicate rows in the original dataframe, Just change the value of Keep to False
df.drop_duplicates('Zone',keep=False)

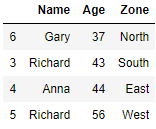
Drop Duplicates in a group but keep the row with maximum value
We will keep the row with maximum aged person in each zone. So we will sort the rows by Age first in ascending order and then drop the duplicates in Zone column and set the Keep parameter to Last.
df.sort_values('Age',ascending=True).drop_duplicates('Zone',keep='last')
Drop Duplicates in a group but keep the row with minimum value
We will keep the row with minimum aged person in each zone. So we will sort the rows by Age first in descending order and then drop the duplicates in Zone column and set the Keep parameter to Last.
df.sort_values('Age',ascending=False).drop_duplicates('Zone',keep='last')
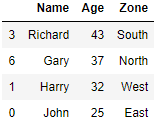
Drop Duplicates based on condition
We will remove duplicates based on the Zone column and where age is greater than 30
df[df.Age.gt(30) & ~(df.duplicated(['Zone'])) ]
Drop Duplicates across multiple Columns using Subset parameter
You can drop duplicates from multiple columns as well. just add them as list in subset parameter. Our original dataframe doesn’t have any such value so I will create a dataframe and remove the duplicates from more than one column
Here is a dataframe with row at index 0 and 7 as duplicates with same
import pandas as pd
df = pd.DataFrame({'Name' : ['John','Harry','Gary','Richard','Anna','Richard','Gary','John'], 'Age' : [25,32,37,43,44,56,37,25], 'Zone' : ['East','West','North','South','East','West','North','West']})

Now drop one of the two rows by setting the subset parameter as a list of column
df.drop_duplicates(subset=['Name','Age'])
Drop Duplicates from Series
We can also drop duplicates from a Pandas Series . here is a series with multiple duplicate rows
a = pd.Series([1,2,3,3,2,2,1,4,5,6,6,7,8], index=[0,1,2,3,4,5,6,7,8,9,10,11,12])
a

Drop Duplicates and reset Index
We will remove the duplicates from series index and reset the index using reset_index() function else it will have the original index from the Series after dropping the Duplicates
a.drop_duplicates().reset_index(drop=True)